Till now, we had handwritten the code for producer and client to send and receive the data. There are many occasion when we need to perform some additional operation on the data that is present in Partition. i.e. find the message/data for invoice that is present on a particular date or having amount value greater than a particular figure. Agreed with you, we can write our own java class and fetch the value from topic and recalculate it but don’t you think it would be really great if we can get this ready-made filter available and for this purpose we have Apache Kafka Stream. It help is performing operation like filtering, calculating, formatting, bifurcating, cosmetic changes in the message etc.
For Apache kafka stream it is a mandate that it should take the data from any topic i.e. we cannot feed data from the outside world to kafka stream.
Let take one example.
Step 1:- First we need to add few of the maven dependensies for the same in our pom.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>2.7.0</version></dependency> we will also use the gson library to parse the data<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.8.6</version></dependency><dependency> <groupId>io.dropwizard.metrics</groupId> <artifactId>metrics-core</artifactId> <version>4.1.16</version></dependency> |
Step 2:-
Lets create a java class in this class we will have following four step
1- Create properties
2- Create topology
3- build topology
4- start stream application
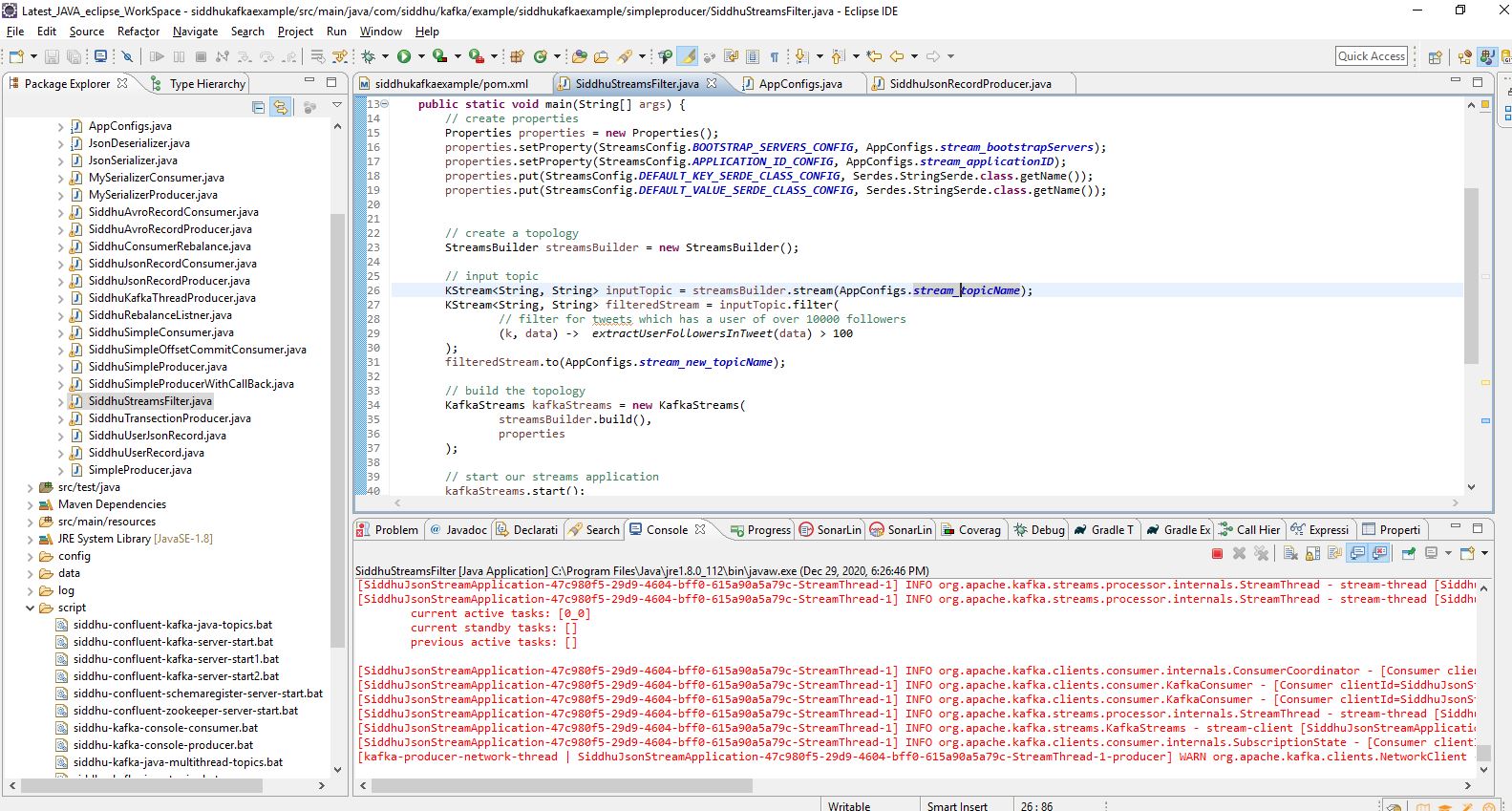
1:- SiddhuStreamsFilter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | package com.siddhu.kafka.example.siddhukafkaexample.simpleproducer;import java.util.Properties;import org.apache.kafka.common.serialization.Serdes;import org.apache.kafka.streams.KafkaStreams;import org.apache.kafka.streams.StreamsBuilder;import org.apache.kafka.streams.StreamsConfig;import org.apache.kafka.streams.kstream.KStream;import com.google.gson.JsonParser;public class SiddhuStreamsFilter { public static void main(String[] args) { // create properties Properties properties = new Properties(); properties.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, AppConfigs.stream_bootstrapServers); properties.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, AppConfigs.stream_applicationID); properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.StringSerde.class.getName()); properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.StringSerde.class.getName()); // create a topology StreamsBuilder streamsBuilder = new StreamsBuilder(); // input topic KStream<String, String> inputTopic = streamsBuilder.stream(AppConfigs.stream_topicName); KStream<String, String> filteredStream = inputTopic.filter( // filter for tweets which has a user of over 10000 followers (k, data) -> extractUserFollowersInTweet(data) > 100 ); filteredStream.to(AppConfigs.stream_new_topicName); // build the topology KafkaStreams kafkaStreams = new KafkaStreams( streamsBuilder.build(), properties ); // start our streams application kafkaStreams.start(); } private static JsonParser jsonParser = new JsonParser(); @SuppressWarnings("deprecation") private static Integer extractUserFollowersInTweet(String data){ // gson library try { return jsonParser.parse(data) .getAsJsonObject() .get("pinnumber") .getAsInt(); } catch (NullPointerException e){ return 0; } }} |
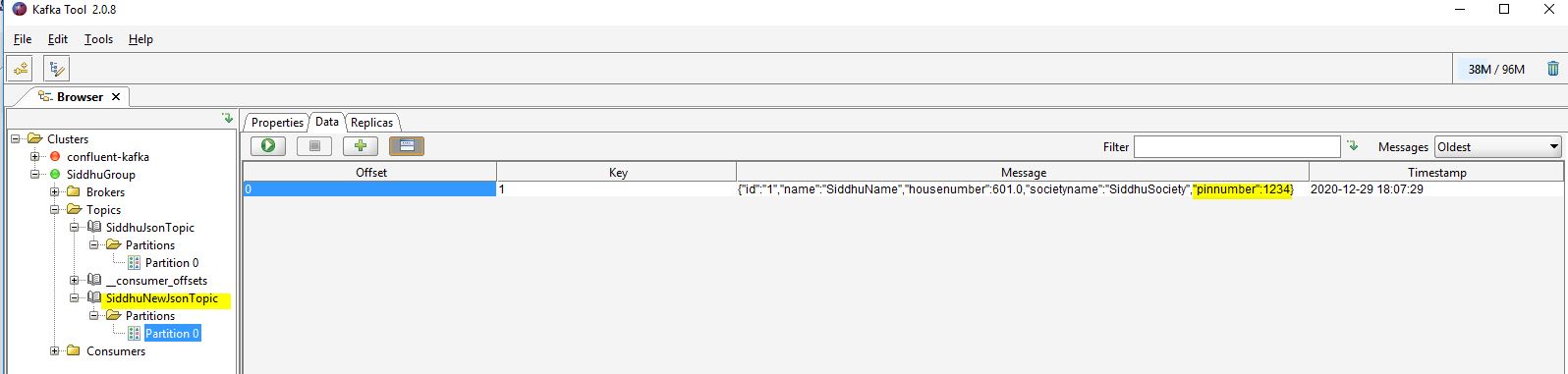
Let’s insert some record into our Topic. We are inserting two record one having pinnumber greate than 100 and other less than 100. As shown below

Now lets run our class as suggested in the class it will traverse all the jason record and check the pinnumber if it is greater than 100 then it will create a new topic named as SiddhuNewJsonTopic and insert that record inside it.
Download the code from https://github.com/shdhumale/siddhukafkaexample.git

No comments:
Post a Comment