What is Apache Kafka
As per the defination on site it “open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.”
This means it act a messaging bus in mid of the two application so that one application generate the data and other consume this generated data either as a live streaming or as batch stream. This application can be either DB, Web any S/W applications.
How it work?
It act as a middle men work. it sits between producer application and consumer application and decoupled them. There are bright chances that they even might not be knowing each other.
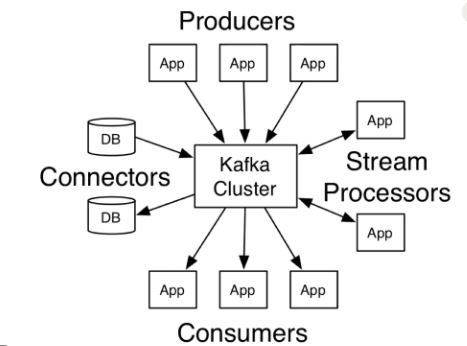
Where it come from and why is the need of this system?
It is developed by Linkedin and open source in 2011. The main reason why this approach was needed is because lots of data was flowing from the Producer i.e. web, mobile, other application and this data was expected to be consume by other system like analytical, run time suggestion etc. Storing the data in DB and asking them to collect from it is a very slow process and also not user-friendly. As the new system added in to the ecosystem more complexity is added i.e. protocol they used https, http, FTP, SFTP, JDBC, TCP/IP etc and even the data that is flow between them is of different type i.e. some use json other uses xml, avro etc. To handle this we required a system that work on highthrough put and handle this efficietly with out any overhead.
Where we can apply this solution?
This can be applied in the situation given below
1- Breaking long running process so that system does not get hault on that movement
2- When large number of application need to be intracted with each other
3- If our echo system is bigger and need frequent addition/update of system to fullfill the purpose.
4- It we need high throughput with large amount of processing data
5- If we need large number of system with different data consumtion to talk each other.
6- It we want fault tolerace, self healing system
7- Data integration
8- Microservice architecture for stream processing
9- Real time data processing data warehousing
and the list is end less usecase and possibilities.
Evalution of Kafka:-
In the begining the Kafka was developed in linkedin only for caterring the below integration of system

for this they had developer
1- Kakfa Broker :- the heart of Kakfa where it sit and perform all the operation of taking the data from the producer. Storing it to its HD i.e. using topic , partition etc and allowing the consumer to consume it as on when needed.
2- JAVA api i.e. producer and client api. :- Producer JAVA API uses to send data from the producer application to Broker and Consumer JAVA API use to consume the data from Broker to client for further respective process.
Further in due course of time its need and requirement changes and Kafka develop itself to further concept like
3- Kakfa Connect :- Use to provide ready made connect for producer and consumer so that we did not required code to writes.
4- Kafka Stream :- Use to process the data when they are in topic before seding it to consumer i.e.transfomation, filteration, complex logic etc.
5- KSQL :- This the latest form in whihc Kafka is preparing to declare it as a perstance system and can be quired with SQL structure.
So the Eco system of the Apache Kafka consist of Kafka broker, client API [producer and consumer], connect, streams, ksql
Now let’s discuss the core concept of Apache Kafka. These are some of the terminology that we are going to use though out the Kakfa family discussion.
‘-producer :- Apps used to produce the data
‘-consumer:- Apps used to consume the data
‘-broker:- Act as a middle man that facilitate the work of producer and consumer to use their data.
‘-cluster:- As it is a distributed system for high throughput we need the broker to run in cluster environment. Where in we have many machines in which we have individual topic run in a cluster environment where they know each other and can talk with each other.
‘-topic :- This is the place where message or data is stored in Kafka. You can consider this as an Table in DBMS.
‘-partition :- As the topic can be huge in nature and size for scalability and performance and security it is divided into part and each part is know as partition. This partition is stored in broker.
‘-offsets :- This is an autogenerated and read-only number provided to partition when the data is stored. It is like pk in RDDMS.
‘-consumer groups:- to increase the performance of the consumner they are tag in single group depending on their name so that they can share the work given to them. We can have max 500 consumer in a group.
‘-Replication factor :- for security purpose the data in the partition is replicated using this replication factor if it is2 then we had one original partition and duplicate.
‘-Partition factors :- This will indicate how many partitions can be done for a single topic. General practice is if you have broker less than 12 always 2* no of broker= number of partitions.
‘-Leader-follower :- Now as we have replication factor which duplicate the partition we must declare one of the partition as leader which will be used for update and read i.e. take the request from producer and also consumer for reading and other as read only for fault tolerance concept.
It is also good to see the competitor in the market for Apache KAFKA i.e. RabbitMQ and ActiveMQ. The reason why Apache Kafka has better handle
1- They work on pub sub method
2- They can store the data/message
3- IT can also behave as a queue if required.
4- IT is fault tolerance, high throughput and easy to maintain
5- Open source with lots of tools.
6- Provide large number of API client in different Language like java, python, node etc.
7- Easy learning curve and large follower groups.
8- highly configurable and easy to manage and understand this configuration.
In next series we will try to use the core concept of Apache Kafka programmatically using java api i.e. broker, producer and consumer API and also CLI tool.

No comments:
Post a Comment