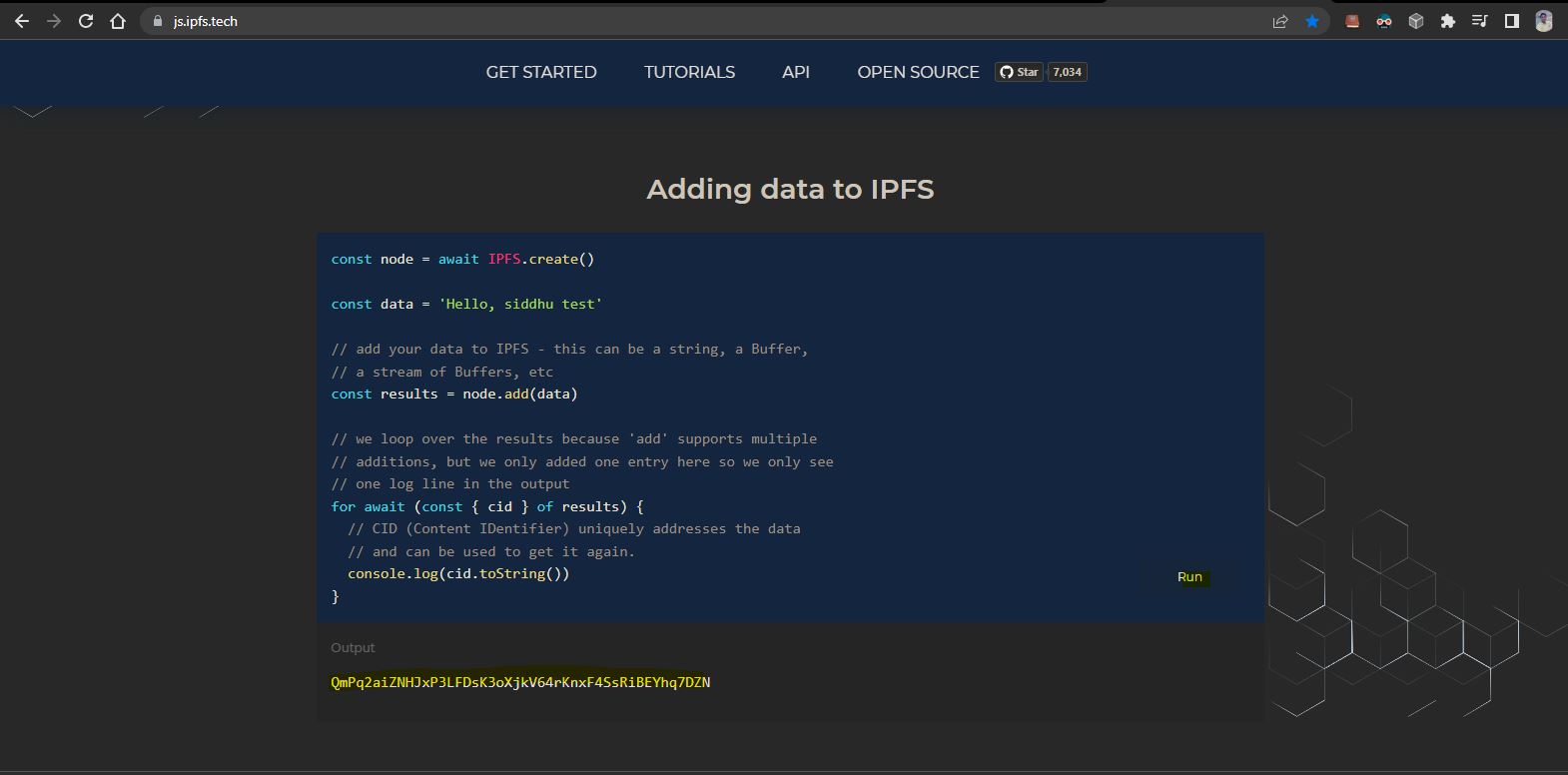
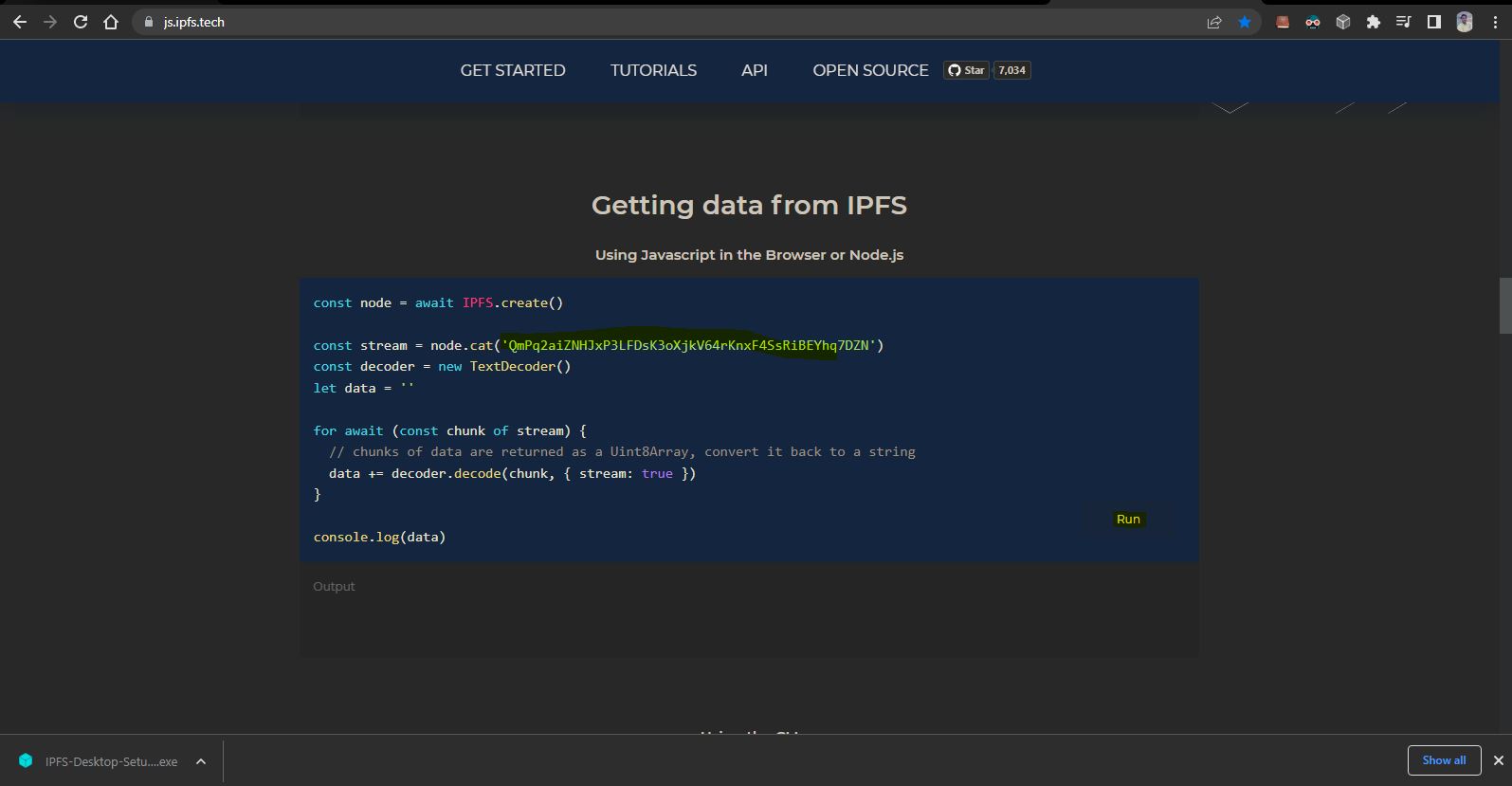
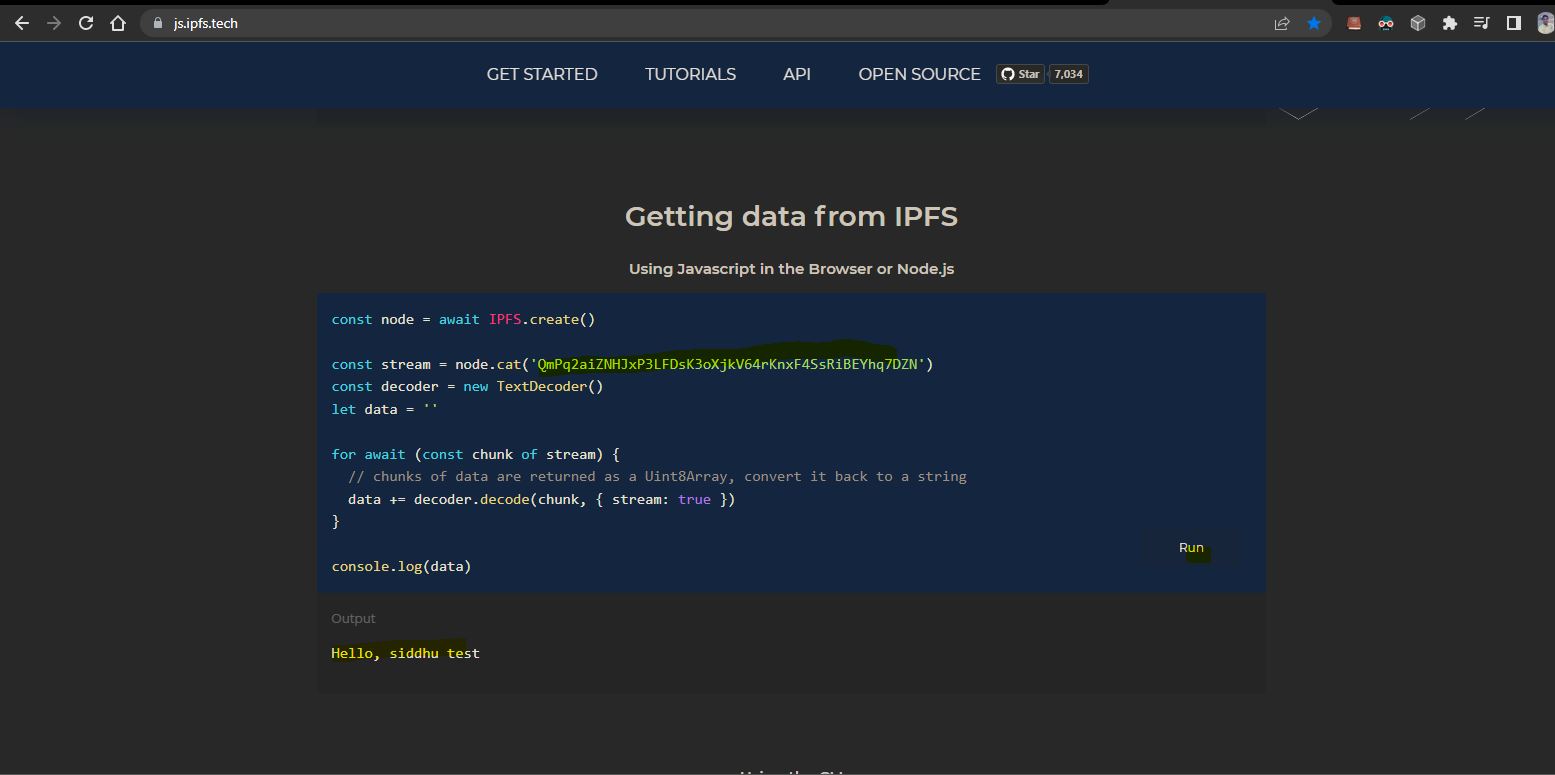
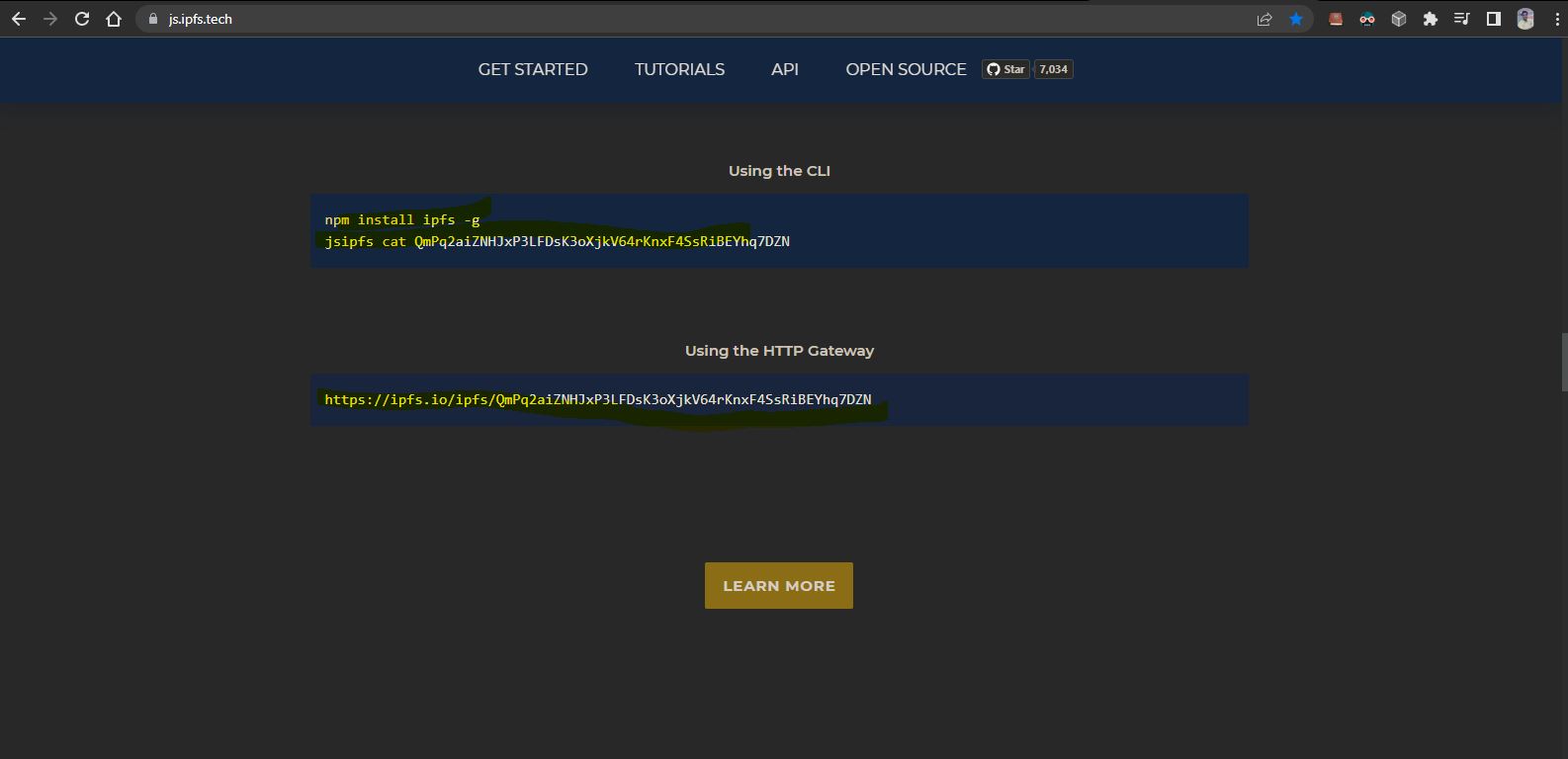
Note: We are using STS as IDE you can use any your favrouite IDE.
First create a simple SpringBoot application as showb below
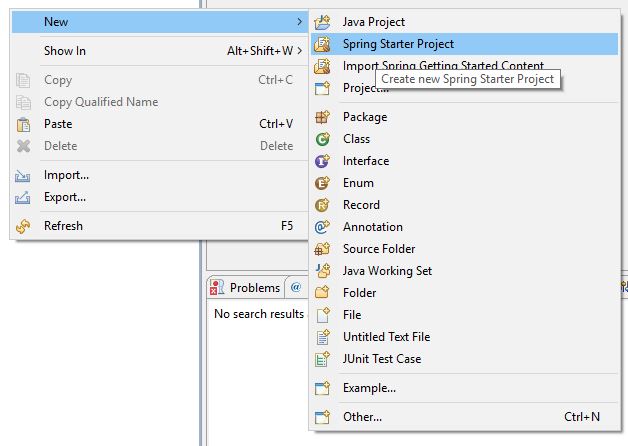
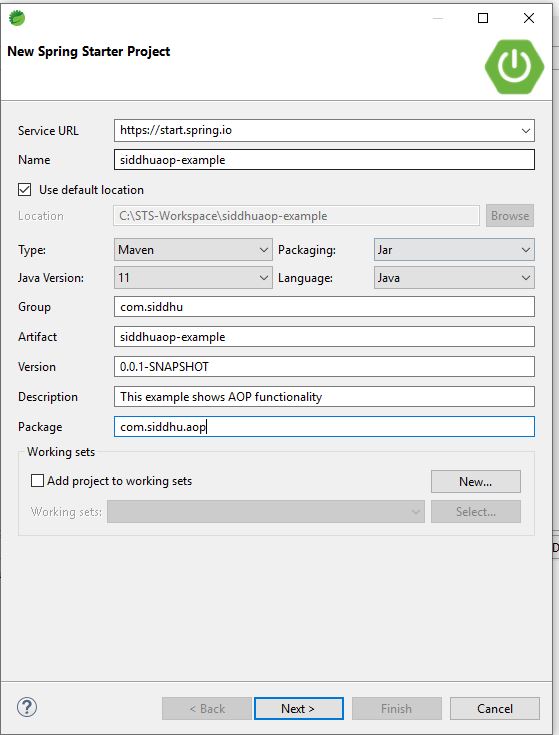
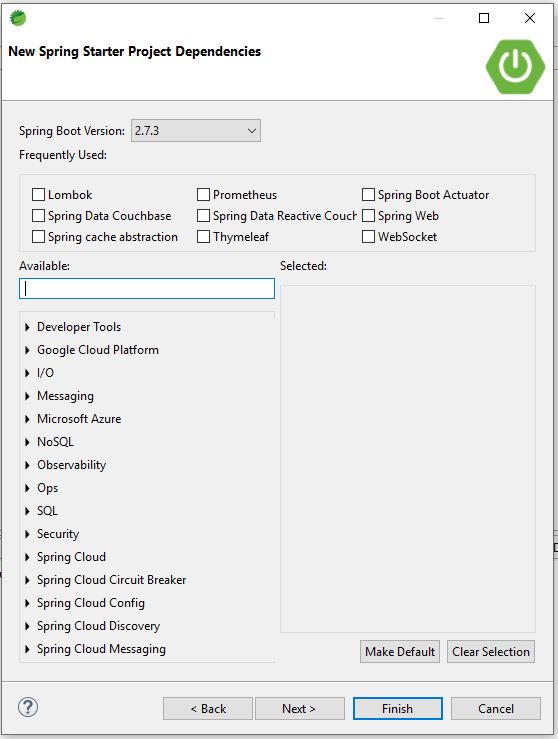
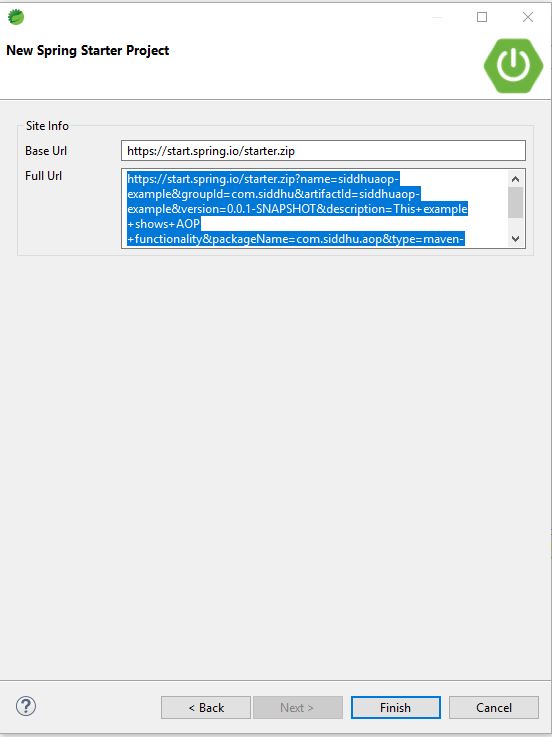
https://start.spring.io/starter.zip?name=siddhuaop-example&groupId=com.siddhu&artifactId=siddhuaop-example&version=0.0.1-SNAPSHOT&description=This+example+shows+AOP+functionality&packageName=com.siddhu.aop&type=maven-project&packaging=jar&javaVersion=11&language=java&bootVersion=2.7.3

Now lets add the AOP dependecies in pom.xml as given below.
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>
Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<groupId>com.siddhu</groupId>
<artifactId>siddhuaop-example</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>siddhuaop-example</name>
<description>This example shows AOP functionality</description>
<properties>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Now lets create a compoenent class and call it in our main springboot application like below
package com.siddhu.aop;
import org.springframework.stereotype.Component;
@Component
public class siddhucomponent {
public void showLog()
{
//log
//security
//transaction
System.out.println("From SiddhuComponent class");
}
}
package com.siddhu.aop;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
@SpringBootApplication
public class SiddhuaopExampleApplication {
@SuppressWarnings("resource")
public static void main(String[] args) {
//SpringApplication.run(SiddhuaopExampleApplication.class, args);
// Annotation based spring context
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.scan("com.siddhu.aop");
context.refresh();
siddhucomponent objsiddhucomponent = context.getBean(siddhucomponent.class);
objsiddhucomponent.showLog();
}
}
now when we run the class we will get output as
12:43:49.937 [main] DEBUG org.springframework.jmx.export.annotation.AnnotationMBeanExporter – Autodetecting user-defined JMX MBeans
From SiddhuComponent class
Now generally in our class we have some common code i.e. logging, security and transaction which we can say an cross cutting consern we can either add this number of line in all the method but that is not good way of coding additional we can create a class and create a method in it with this common code i..e log(), security() and transaction() and then create an instance of this class and add in all the class ..but as said again this is not a good practise so best is to use the concept of AOP like given below
Before using this concept we need to understand some annotation i.e.
cross cutting concern :- This are the common line of code that we are planning to move from all main class to this @aspect class
Advice:- this annotation says when we want to do the things i.e before after etc.
pointcut:- this show on which method this need to be executed.
lets create a component class with Aspect behaviour as shown below
package com.siddhu.aop;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
//cross cutting concern :- This are the common line of code that we are planning to move from all main class to this @aspect class
//Advice:- this annotation says when we want to do the things i.e before after etc.
//pointcut:- this show on which method this need to be executed.
@Component
@Aspect
public class siddhuhelperaop {
public void log()
{
System.out.println("called fom siddhuhelperaop");
}
}
Now we need to add advice and point cut this can be done with belwo line above the cross cutting consern method log()
@Before(“execution(public void showLog())”)
so the final aspect class will be
package com.siddhu.aop;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
//cross cutting concern :- This are the common line of code that we are planning to move from all main class to this @aspect class
//Advice:- this annotation says when we want to do the things i.e before after etc.
//pointcut:- this show on which method this need to be executed.
@Component
@Aspect
public class siddhuhelperaop {
@Before("execution(public void showLog())")
public void log()
{
System.out.println("called fom siddhuhelperaop");
}
}
Now lets run the applicaiton one more time and you will see this output.
12:56:50.989 [main] DEBUG org.springframework.jmx.export.annotation.AnnotationMBeanExporter – Autodetecting user-defined JMX MBeans
called fom siddhuhelperaop
From SiddhuComponent class
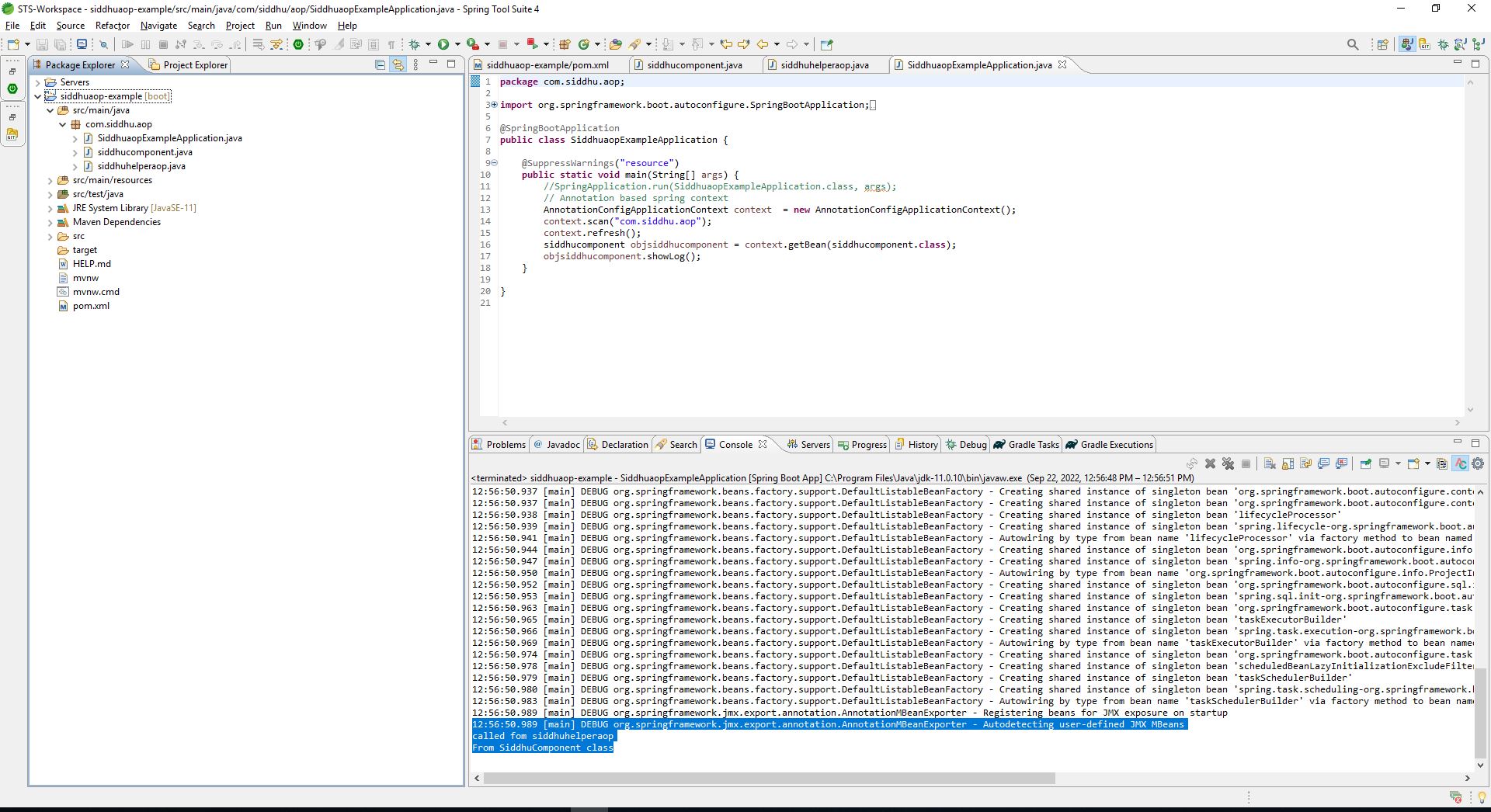
This shows that our common concern of loggin is called as per the AOP aspect using before advice and pointcut method showLog() this was we can add other security , transaction etc aspect to the project without touching the main bussiness logic.
you can download the code from below locations.
https://github.com/shdhumale/siddhuaop-example.git