Before starting Retrieval Augmented Generation (RAG), we need to first understand.
1- What is AI,Machine Learning & Deep Learning etc. As this post is most on using RAG concept to read the PDF and generate answer from the user questions we will just try to bullet few of the points
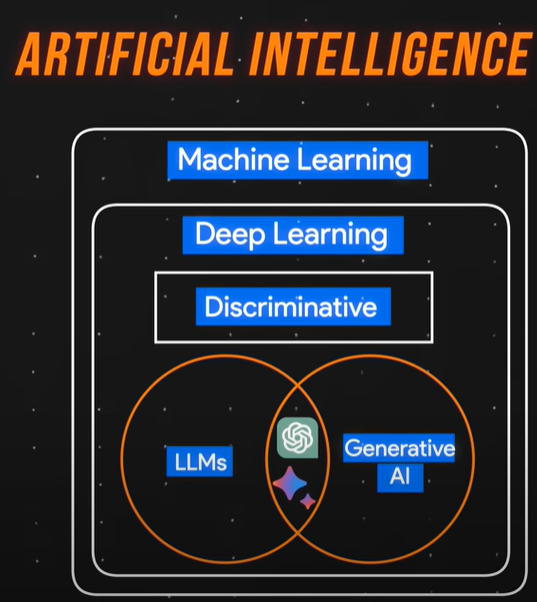
 Understanding Artificial Intelligence and Its Subfields
Understanding Artificial Intelligence and Its Subfields- Artificial intelligence (AI) is a broad field encompassing various subfields.
- Machine learning is a subset of AI, focusing on training models to make predictions from data.
- Deep learning, a subset of machine learning, utilizes artificial neural networks inspired by the human brain.
 Types and Differences of Machine Learning Models
Types and Differences of Machine Learning Models- Supervised learning utilizes labeled data for training, while unsupervised learning uses unlabeled data.
- Supervised learning models make predictions based on labeled data points, while unsupervised learning identifies patterns in unlabeled data.
- After making predictions, supervised learning models compare them to training data to improve accuracy.
- Understanding Deep Learning and Its Applications
- Deep learning involves training models with artificial neural networks, enabling complex pattern recognition.
- Semi-supervised learning allows models to learn from a combination of labeled and unlabeled data.
- Deep learning models can be discriminative, focusing on classifying data points, or generative, creating new data based on learned patterns.
 Generative AI Model Types and Applications
Generative AI Model Types and Applications- Generative AI creates new samples such as text, images, video, or 3D assets based on learned patterns.
- Different types of generative AI models include text-to-text, text-to-image, text-to-video, text-to-3D, and text-to-task models.
- These models have diverse applications ranging from content creation to specific task automation.
 Large Language Models (LLMs) and Fine-Tuning
Large Language Models (LLMs) and Fine-Tuning- LLMs are pre-trained with extensive data and then fine-tuned for specific tasks using domain-specific datasets.
- Fine-tuning LLMs with domain-specific data enhances their performance in specialized areas such as healthcare, finance, and retail.
- This approach enables smaller institutions to benefit from LLMs developed by larger companies, improving efficiency and accuracy.
Now lets try to understand what is Retrieval Augmented Generation (RAG) and LangChain
- Retrieval Augmented Generation (RAG) merges generative and retrieval models to produce contextually relevant content.
- RAG combines the strengths of generative models like GPT with the precision of retrieval systems.
- LangChain facilitates interactions with various large language models (LLMs) and enables the creation of Chains to bridge multiple LLMs.
- Vector databases store and process data in vector format, allowing efficient storage, retrieval, and manipulation of vast datasets.
- RAG, LangChain, and Vector Databases work together to interpret user queries, retrieve relevant information, and generate coherent responses.
- Implementing question answering in LangChain involves loading data, splitting documents, and utilizing embeddings and vector databases.
- Hallucinations in Generative AI applications, such as RAG, can be mitigated through targeted queries, rich context incorporation, confidence scores, and human validation loops.
- Evaluating RAG applications involves component-wise and end-to-end evaluations to ensure system quality and effectiveness.
- Ethical considerations, including privacy, bias, fairness, accountability, and transparency, are crucial in the development and deployment of advanced information technologies like RAG, LangChain, and Vector Databases.
- The collaboration between RAG, LangChain, and Vector Databases enhances content generation, enables more advanced virtual assistants and chatbots, and ensures technology serves as an augmentation of human capabilities.
Lets try to understand our usecase now
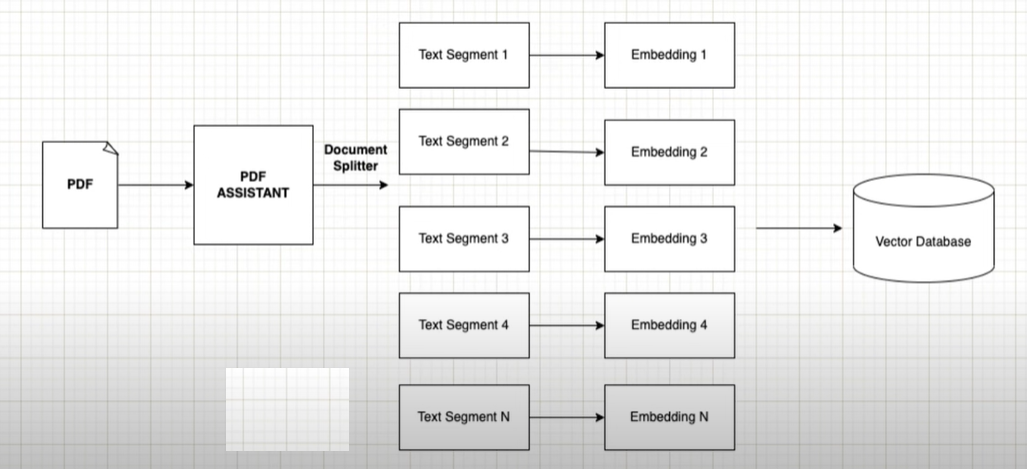
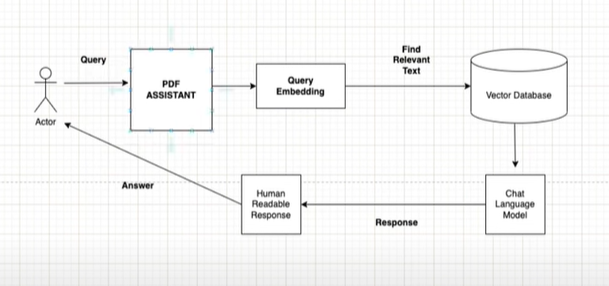
In our usecase user upload the PDF files from which he/she expect the generative answer. we upload the data in Vector Database Astra from casssandra and we are using Open AI LLM.
So lets first cretat OpenAI API key.
Then create a Vectore Database using Astra and note down the DB namd. Name Space , DB id and Token ID. We will need this in our code.
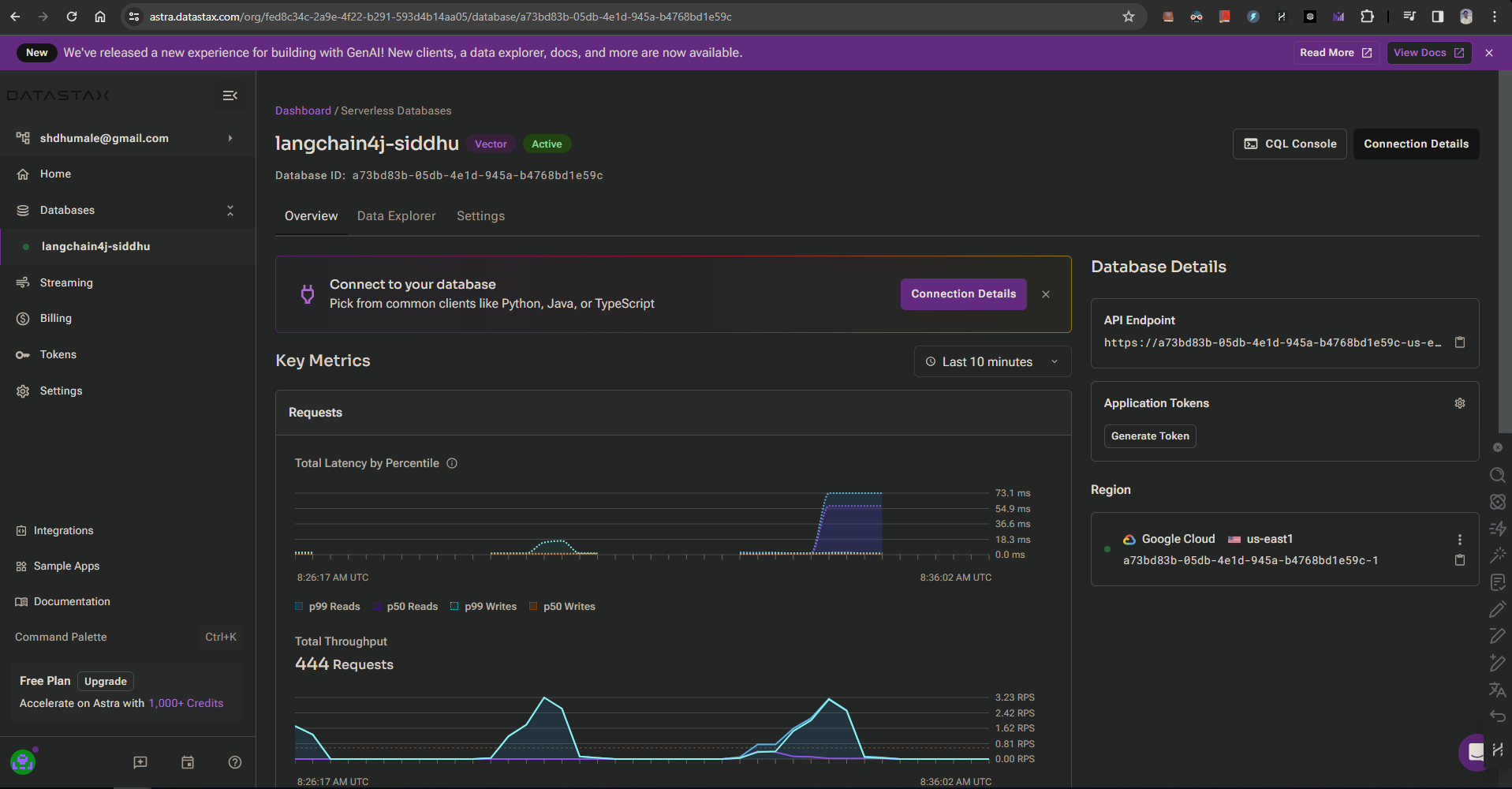
Astra:-
DB name :-langchain4j-siddhu
Name Space:- langchain4jsiddhu
db id: ad1e59c Token Details :- AstraCS:MZXz33a7bbb
Now lets create a maven project and following dependencies in it
1- pom.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.1</version> </parent> <groupId>com.siddhu</groupId> <artifactId>langchain4j-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>langchain4j-demo</name> <description>This Springboot application shows the use of langchain4j</description> <properties> <java.version>17.0.5</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.25.0</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>0.25.0</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId> <version>0.25.0</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-pdfbox</artifactId> <version>0.25.0</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-cassandra</artifactId> <version>0.25.0</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build></project> |
2- SiddhuPdfAssistantApplication
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | package com.siddhu;import dev.langchain4j.data.document.Document;import dev.langchain4j.data.document.parser.apache.pdfbox.ApachePdfBoxDocumentParser;import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;import jakarta.annotation.PostConstruct;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import java.net.URISyntaxException;import java.net.URL;import java.nio.file.Path;import java.nio.file.Paths;import static dev.langchain4j.data.document.loader.FileSystemDocumentLoader.loadDocument;@SpringBootApplicationpublic class SiddhuPdfAssistantApplication { private final EmbeddingStoreIngestor embeddingStoreIngestor; public SiddhuPdfAssistantApplication(EmbeddingStoreIngestor embeddingStoreIngestor) { this.embeddingStoreIngestor = embeddingStoreIngestor; } @PostConstruct public void init() { Document document = loadDocument(toPath("cassandra.pdf"), new ApachePdfBoxDocumentParser()); embeddingStoreIngestor.ingest(document); } private static Path toPath(String fileName) { try { URL fileUrl = SiddhuPdfAssistantApplication.class.getClassLoader().getResource(fileName); return Paths.get(fileUrl.toURI()); } catch (URISyntaxException e) { throw new RuntimeException(e); } } public static void main(String[] args) { SpringApplication.run(SiddhuPdfAssistantApplication.class, args); }} |
3- SiddhuChatController
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | package com.siddhu;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import dev.langchain4j.chain.ConversationalRetrievalChain;import dev.langchain4j.data.document.splitter.DocumentSplitters;import dev.langchain4j.model.embedding.AllMiniLmL6V2EmbeddingModel;import dev.langchain4j.model.embedding.EmbeddingModel;import dev.langchain4j.model.openai.OpenAiChatModel;import dev.langchain4j.retriever.EmbeddingStoreRetriever;import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;import dev.langchain4j.store.embedding.cassandra.AstraDbEmbeddingConfiguration;import dev.langchain4j.store.embedding.cassandra.AstraDbEmbeddingStore;import lombok.RequiredArgsConstructor;@RestController@RequestMapping("/api/chat")@RequiredArgsConstructorpublic class SiddhuChatController { //private final ConversationalRetrievalChain conversationalRetrievalChain; private static Logger LOGGER = LoggerFactory.getLogger(SiddhuChatController.class); public EmbeddingModel embeddingModel() { LOGGER.debug("Returning AllMiniLmL6V2EmbeddingModel Instance"); return new AllMiniLmL6V2EmbeddingModel(); } public AstraDbEmbeddingStore astraDbEmbeddingStore() { String astraToken = "<your-astradb-token>"; String databaseId = "<your-database-id>"; LOGGER.debug("Returning AstraDbEmbeddingStore"); return new AstraDbEmbeddingStore(AstraDbEmbeddingConfiguration .builder() .token(astraToken) .databaseId(databaseId) .databaseRegion("us-east1") .keyspace("langchain4jsiddhu") .table("pdfchat") .dimension(384) .build()); } public EmbeddingStoreIngestor embeddingStoreIngestor() { LOGGER.debug("Returning EmbeddingStoreIngestor"); return EmbeddingStoreIngestor.builder() .documentSplitter(DocumentSplitters.recursive(300, 0)) .embeddingModel(embeddingModel()) .embeddingStore(astraDbEmbeddingStore()) .build(); } public ConversationalRetrievalChain conversationalRetrievalChain() { return ConversationalRetrievalChain.builder() .chatLanguageModel(OpenAiChatModel.withApiKey("your-open-api-key")) .retriever(EmbeddingStoreRetriever.from(astraDbEmbeddingStore(), embeddingModel())) .build(); } @PostMapping public String chatWithPdf(@RequestBody String text) { var answer = this.conversationalRetrievalChain().execute(text); LOGGER.debug("Answer provided by the Langchain4j using Astra as Vector DB is - {}", answer); return answer; }} |
Finally put our pdf in resource folder as show below
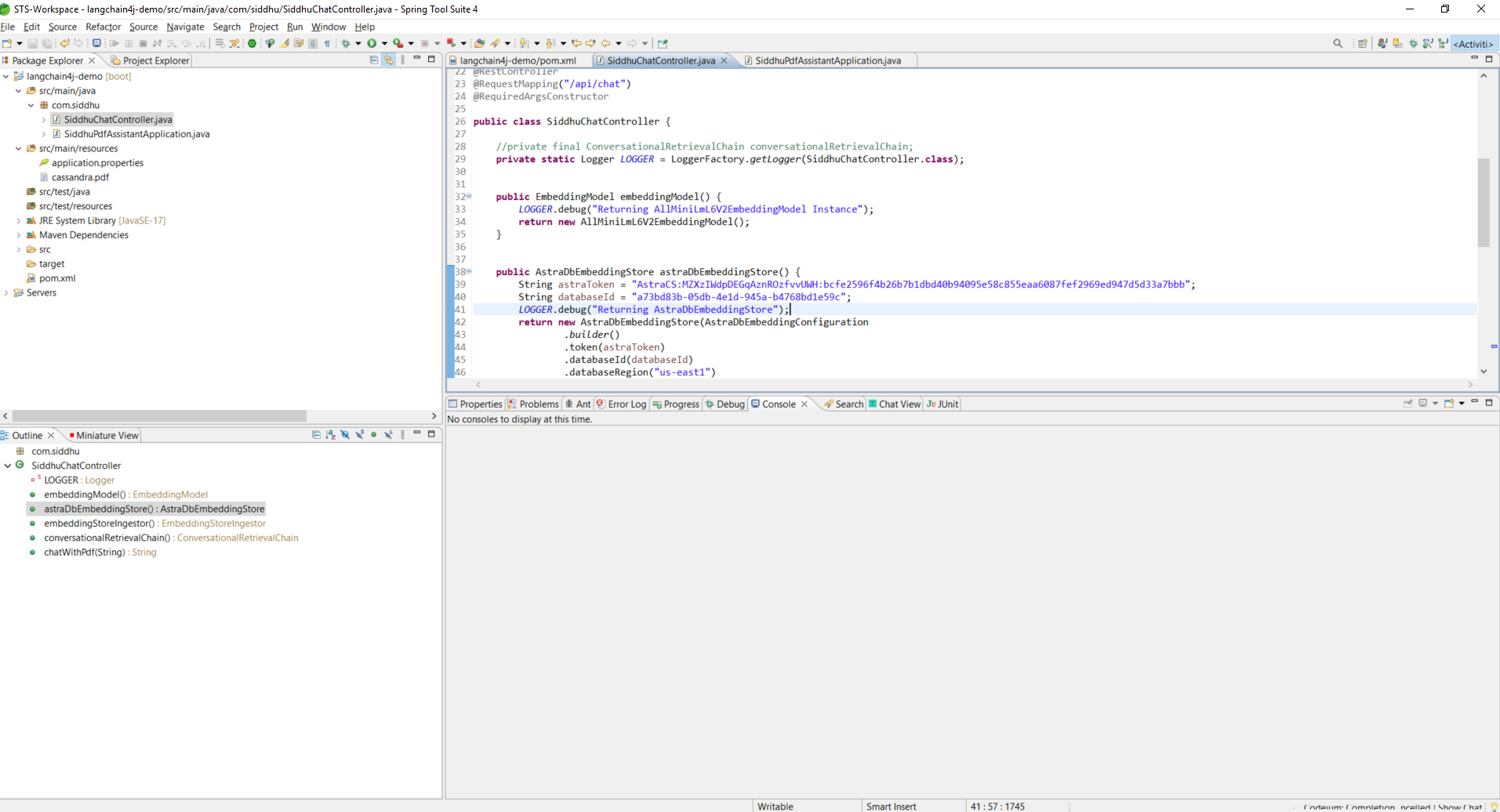
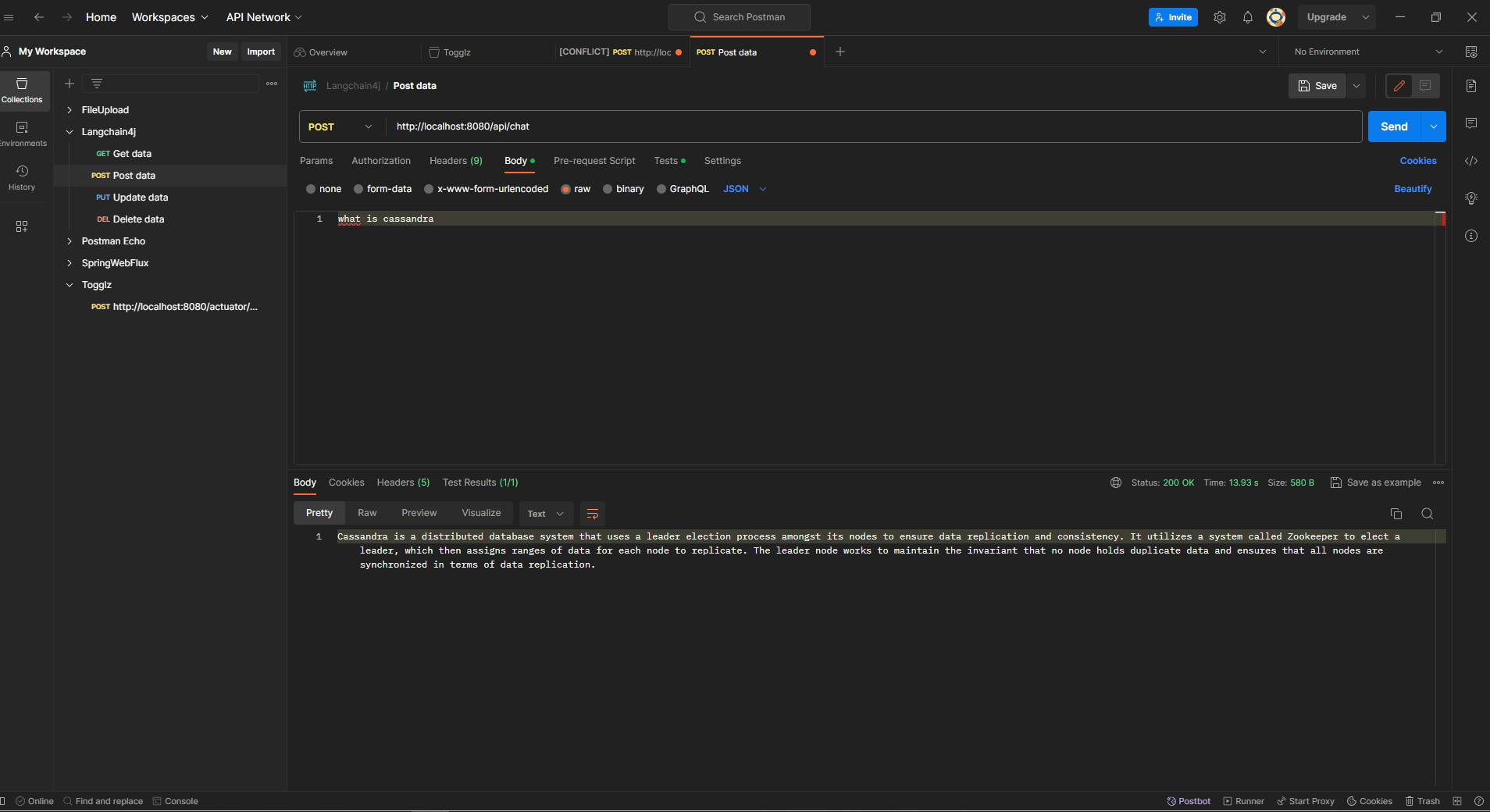
now lets start the application and once started hit the below url using POST man tool
Note:- You can download the source code from belwo location
Git Location :- https://github.com/shdhumale/langchain4j-demo.git