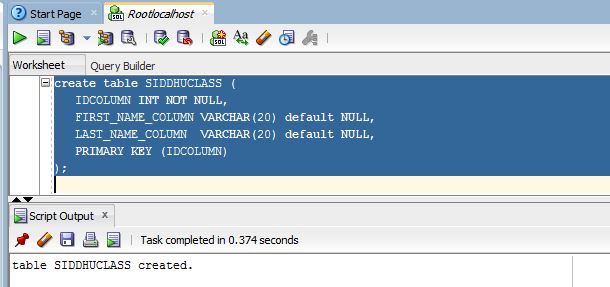
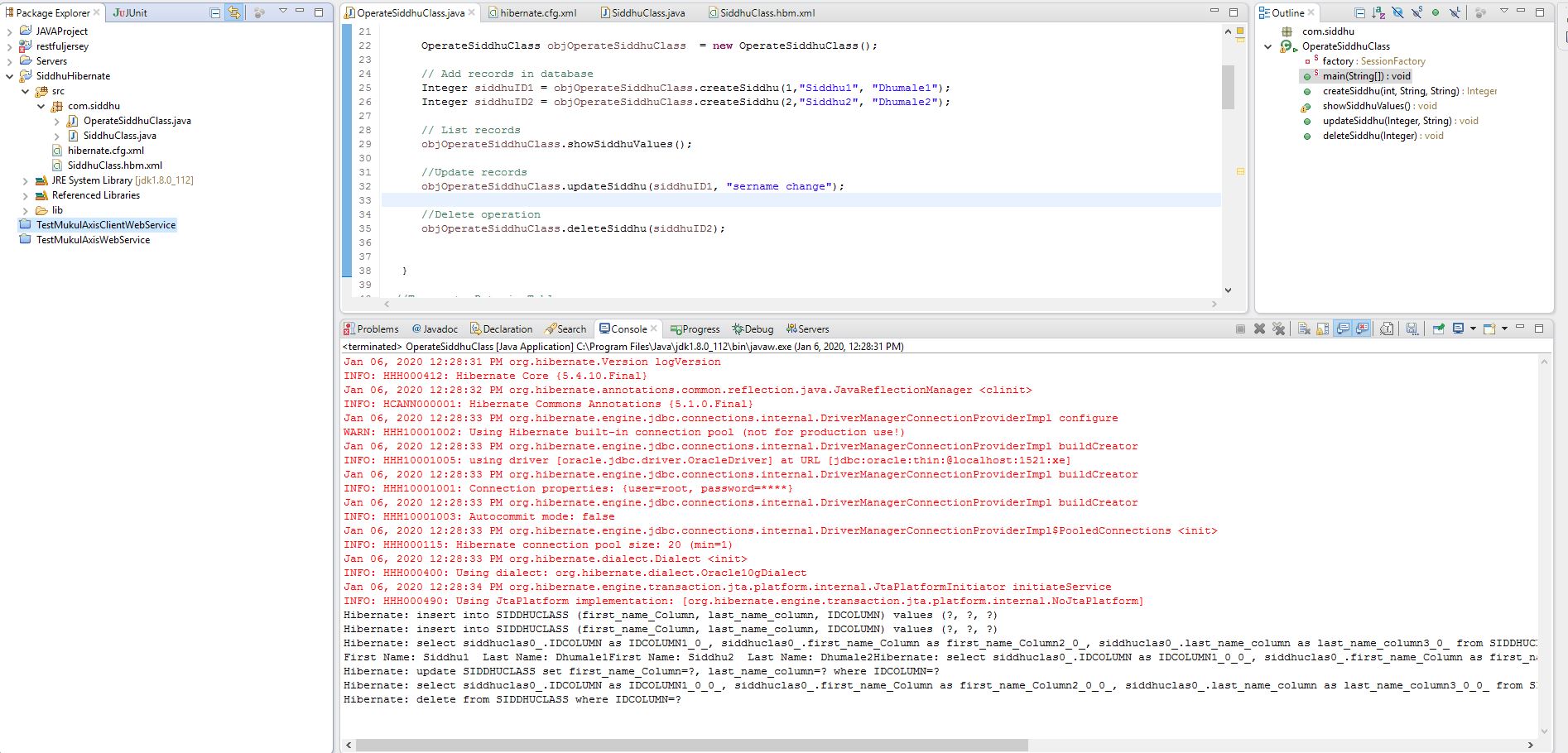
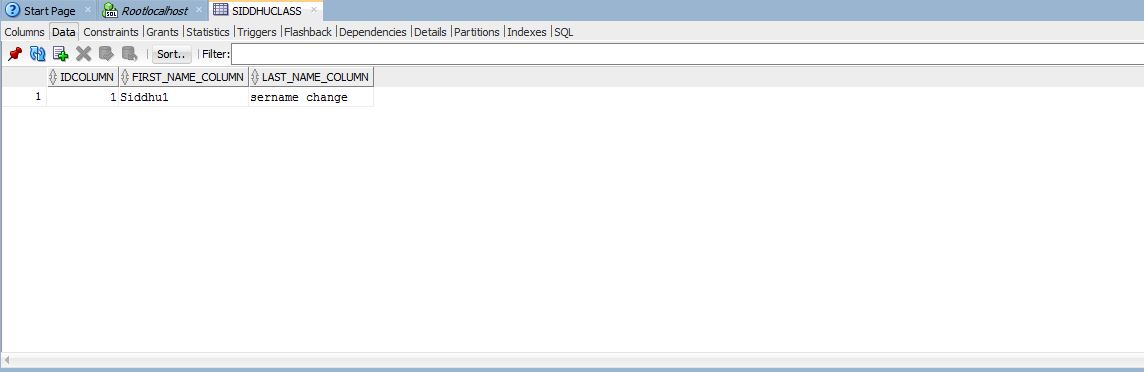
Searching data from UI is one of the main functionality of any application. In case of usig RDBMS as DB for small amount of data we can handle it with SQL query. But when we move to bigdata or nosql DB in that case we need some mechanism through which we can perform Search operation with less cost on performance.
For this purpose we have a beautiful Lucene API. Lucene is created by the founder of Hadoop DB. Lucene is a search engine packaged together in a set of jar files. There are many such search which was build taking base Lucene as base/core heart of search engine Elastic , Solr etc are one of them.
In this blog item we will discuss about Elastic Search engine. But before going in details lets discuss something related to nosql DB. As the name suggest NOSQL DB means this type of DB cannot be queried using query language. In this type of DB data is stored in form of Document and hence it is called as document-base database. This means data is stored in form of document i.e. JSON or XML as documents.
When we discuss about the NOSQL for searching we use Indexing concept.
Index concept is similar to what we have in SQL DB. As you might be knowing we have index in every book. When ever we want to search for any particular topic we find that in index page and then from there we find its particular page. This way it become easy for us to find the required information easily. Same concept is used in performing Index in SQL and NOSQL.
Indexing means -- > Page to words
Inverted indexing means --> Word to Pages
In case of document-base NOSQL with in term of data model DATA is stored in form of documents. Index is made on that documents and each document is made of many fields
in short
Index --> Many documents --> Fields
Further Documents can be classified logical into groups called as Mapping type using Mapping Definitions
Documents --> Mapping Type --> Using Mann Mapping Types
In simple language related to SQL we Index is a database, Type is a table, Documents is record in that table and Fields is table column.
Now lets discuss about Elastic Search. Elastic search engine work on Lucene engine or jar files. It provide additional functionality over the top of Lucene engine. Elastic search comes into the market in late 2010 and with in few years has capture its position on top 3 search engine. It store the data in the form of JSON. It provide rich JAVA REST API to access and perform CRUD operation on data stored as JSON document form. Lets see below example in which we perform CRUD operation on the elastic search.
1- you need to download Elastic search from https://www.elastic.co/downloads/elasticsearch
Download appropriate version depending on your O/S we are using Windows and hence downloading https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-windows-x86_64.zip
2- Unzip and you will get follwing folder
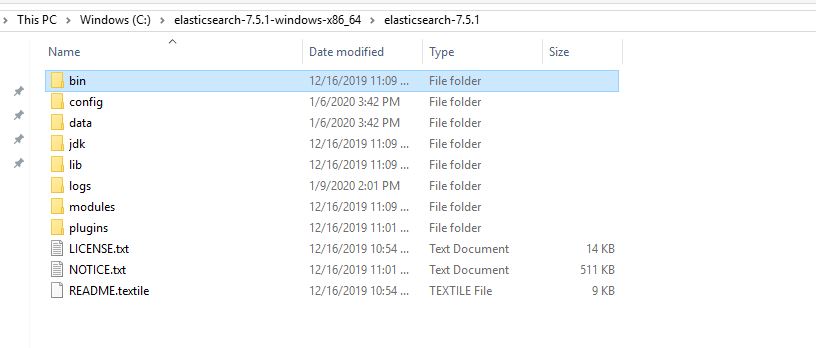
3- Set Environment Variable:-
PATH = C:\elasticsearch-7.5.1-windows-x86_64\elasticsearch-7.5.1\bin
4- Start the Engine using below commands
C:\elasticsearch-7.5.1-windows-x86_64\elasticsearch-7.5.1\bin\elasticsearch.bat
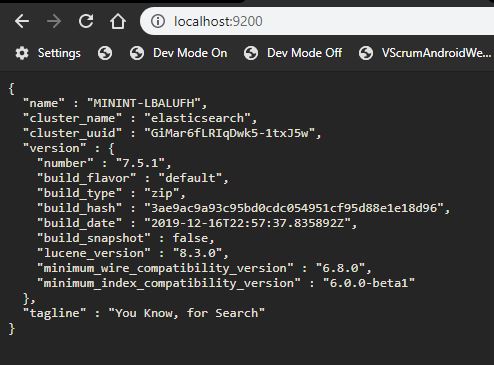
Once the server is started hit this url on the browser http://localhost:9200 and you will get below screen.
Now lets try to perform some of the CRUD operation on Elastic Search engine using POSTMAN tool. AS we know we can fire http REST API call using Postman and can get and manupulate response properly. You can also use SoapUi if needed for the same.
Few this that we need to upderstand when making query using REST call we need to follow fews rules
1- Our request should always follow this patter
http://myserver:portnumber/index/type
Additional Index must be in lower case, otherwise it throws an Exception.
In terms of RDBMS:-
Index= Database
type=Table
document= one single row in that table
field = table column
We also need to know few of the basic ElasticSearch Commands
HTTP Request Type Usage
GET To get/select/read data from ElasticSearch engine
POST To create/update data to ElasticSearch engine
PUT To create/update data to ElasticSearch engine
DELETE To delete existing data from ElasticSearch engine
'- Create operation :-
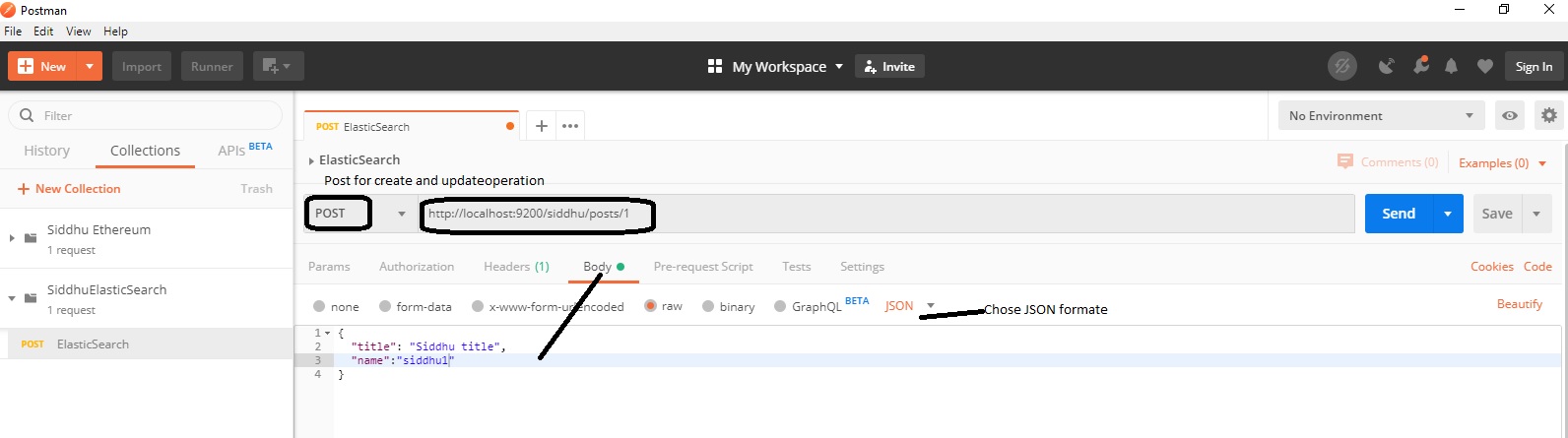
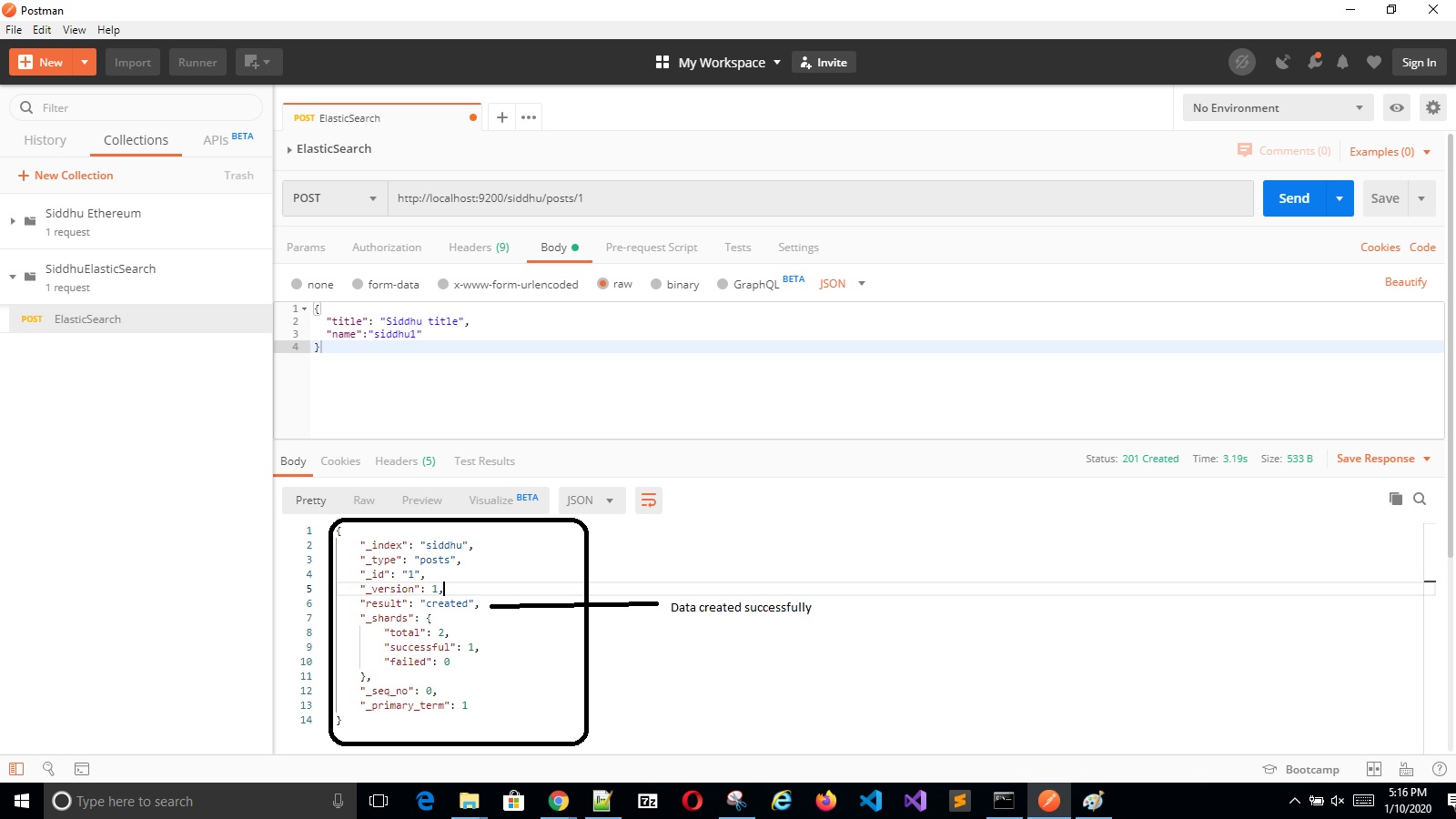

'- Read operation:-
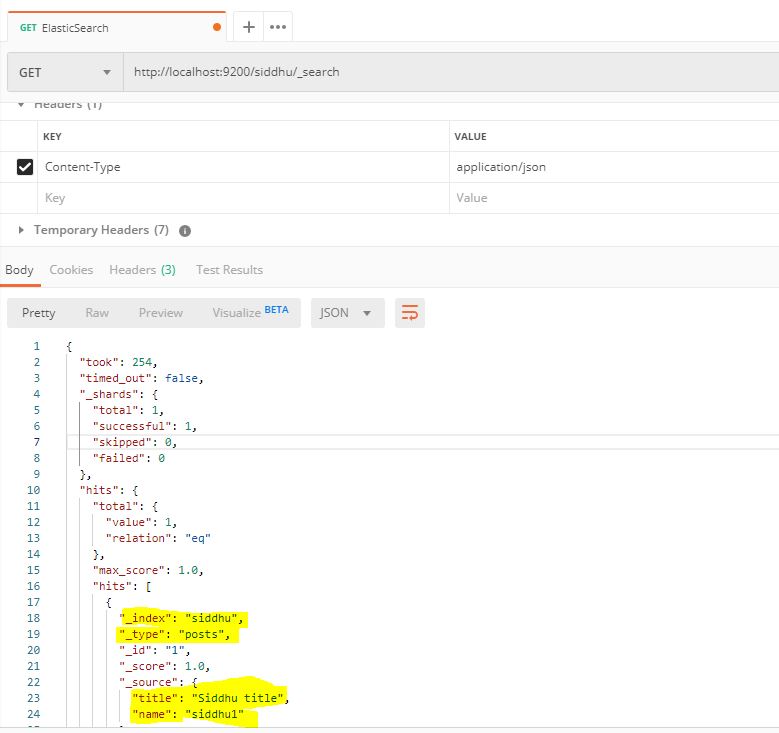
To read data we should use “_search” at the end of the read API URL.
'- Update Operation
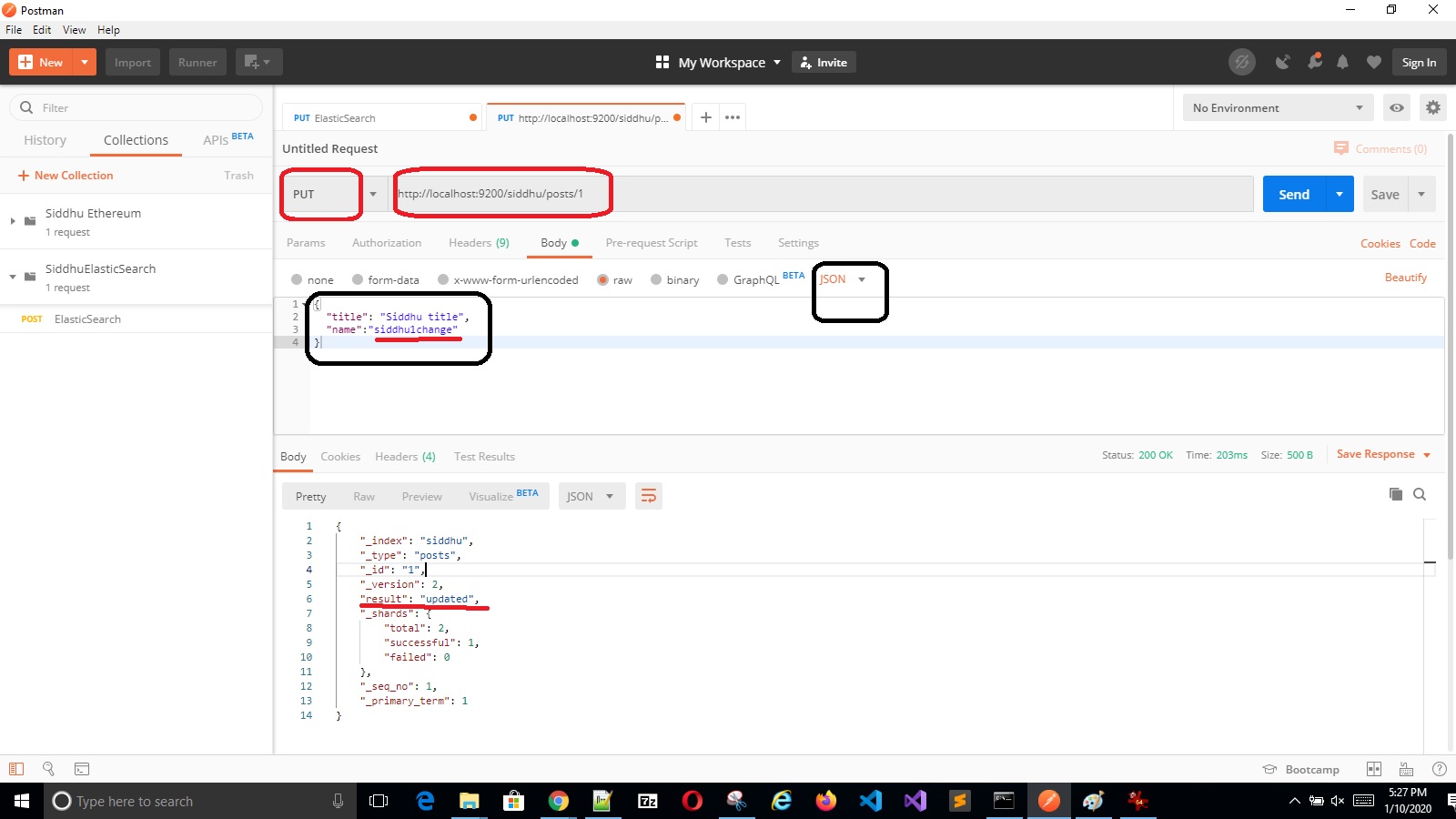
Verifying the data is updated
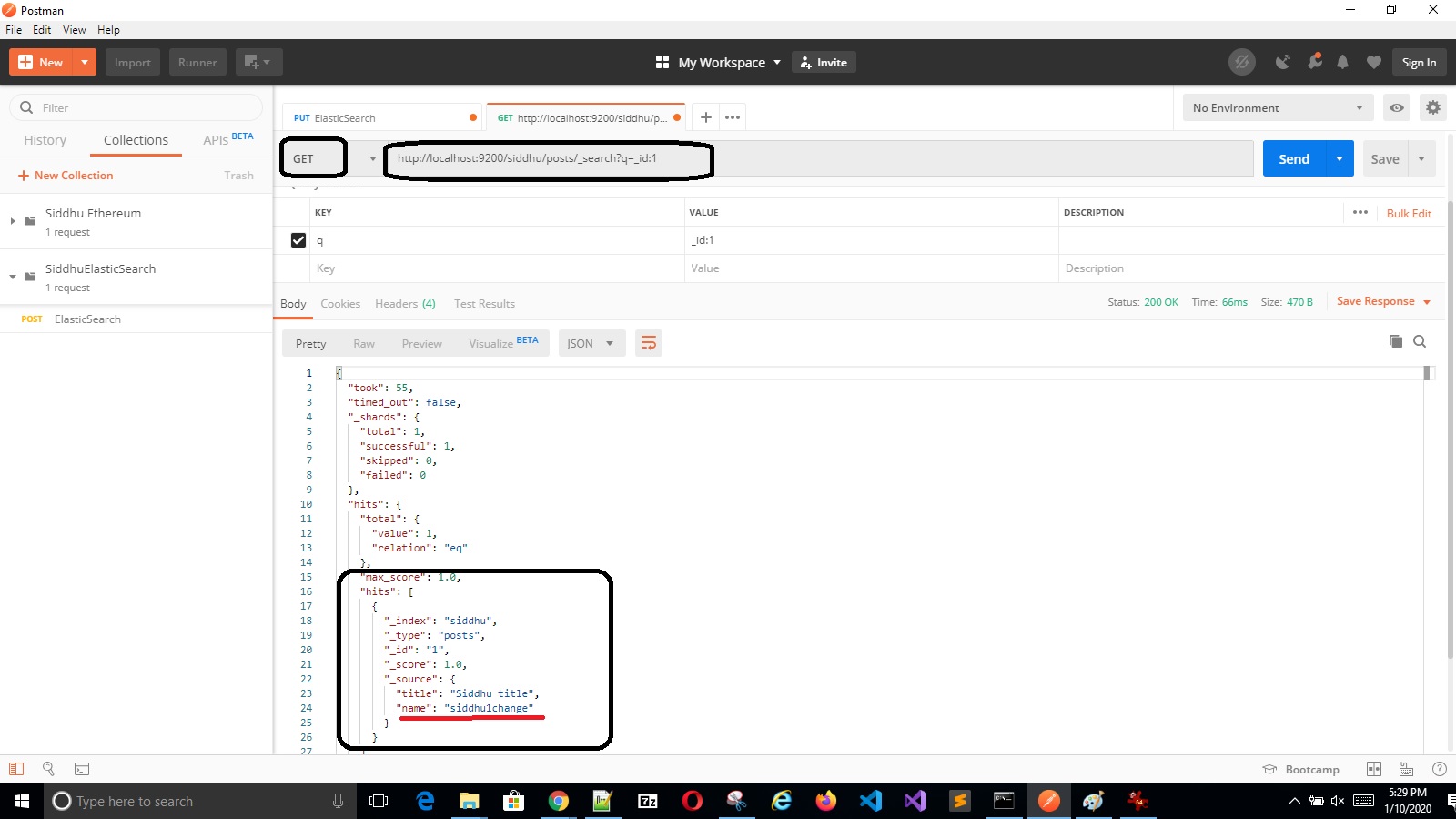
'- Delete Operation
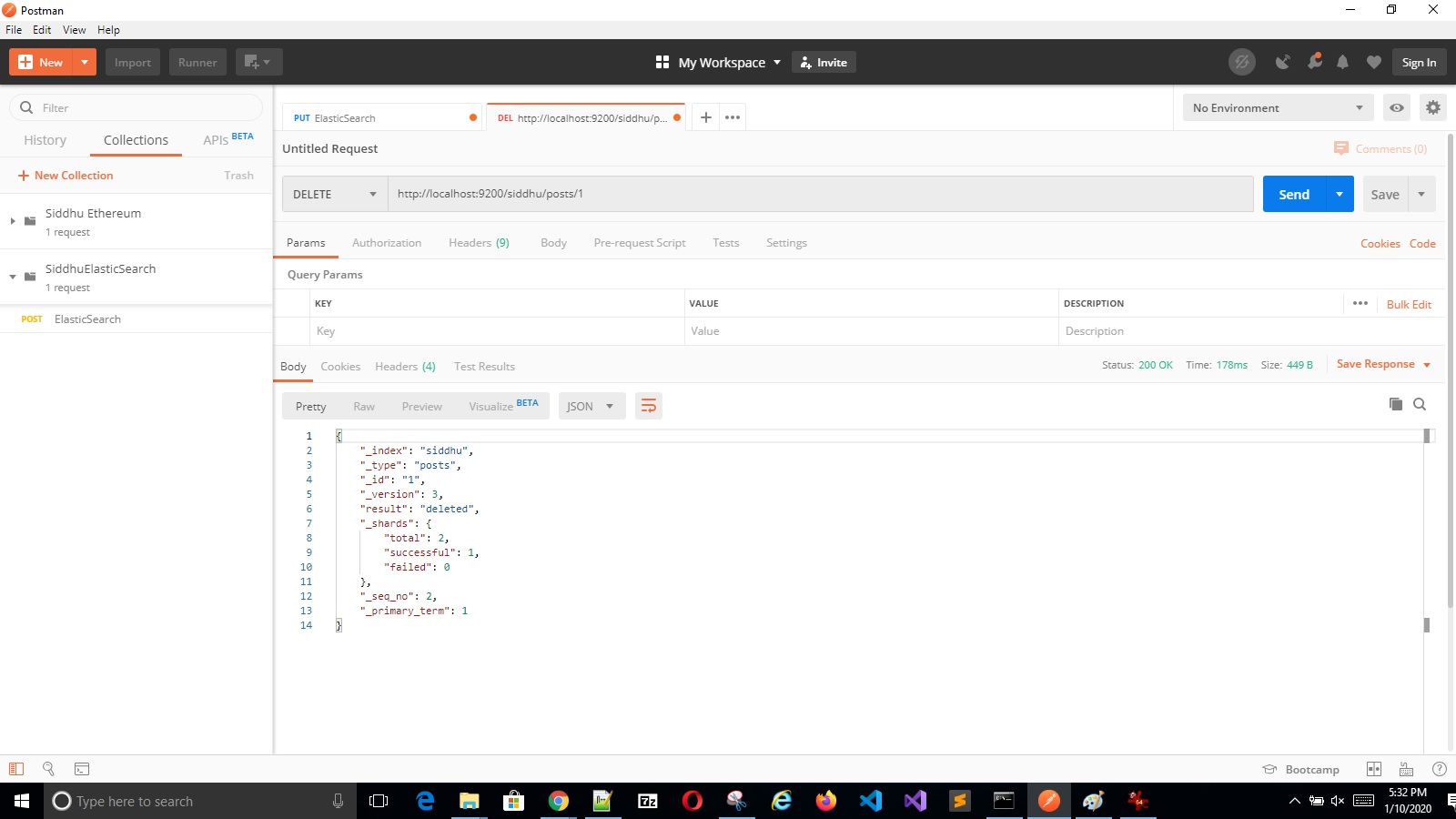
Refer below URL:-
https://www.elastic.co/webinars/getting-started-elasticsearch?baymax=optimize&elektra=product-elasticsearch&storm=hero&rogue=watch-video
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
For this purpose we have a beautiful Lucene API. Lucene is created by the founder of Hadoop DB. Lucene is a search engine packaged together in a set of jar files. There are many such search which was build taking base Lucene as base/core heart of search engine Elastic , Solr etc are one of them.
In this blog item we will discuss about Elastic Search engine. But before going in details lets discuss something related to nosql DB. As the name suggest NOSQL DB means this type of DB cannot be queried using query language. In this type of DB data is stored in form of Document and hence it is called as document-base database. This means data is stored in form of document i.e. JSON or XML as documents.
When we discuss about the NOSQL for searching we use Indexing concept.
Index concept is similar to what we have in SQL DB. As you might be knowing we have index in every book. When ever we want to search for any particular topic we find that in index page and then from there we find its particular page. This way it become easy for us to find the required information easily. Same concept is used in performing Index in SQL and NOSQL.
Indexing means -- > Page to words
Inverted indexing means --> Word to Pages
In case of document-base NOSQL with in term of data model DATA is stored in form of documents. Index is made on that documents and each document is made of many fields
in short
Index --> Many documents --> Fields
Further Documents can be classified logical into groups called as Mapping type using Mapping Definitions
Documents --> Mapping Type --> Using Mann Mapping Types
In simple language related to SQL we Index is a database, Type is a table, Documents is record in that table and Fields is table column.
Now lets discuss about Elastic Search. Elastic search engine work on Lucene engine or jar files. It provide additional functionality over the top of Lucene engine. Elastic search comes into the market in late 2010 and with in few years has capture its position on top 3 search engine. It store the data in the form of JSON. It provide rich JAVA REST API to access and perform CRUD operation on data stored as JSON document form. Lets see below example in which we perform CRUD operation on the elastic search.
1- you need to download Elastic search from https://www.elastic.co/downloads/elasticsearch
Download appropriate version depending on your O/S we are using Windows and hence downloading https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.5.1-windows-x86_64.zip
2- Unzip and you will get follwing folder
3- Set Environment Variable:-
PATH = C:\elasticsearch-7.5.1-windows-x86_64\elasticsearch-7.5.1\bin
4- Start the Engine using below commands
C:\elasticsearch-7.5.1-windows-x86_64\elasticsearch-7.5.1\bin\elasticsearch.bat
Once the server is started hit this url on the browser http://localhost:9200 and you will get below screen.
Now lets try to perform some of the CRUD operation on Elastic Search engine using POSTMAN tool. AS we know we can fire http REST API call using Postman and can get and manupulate response properly. You can also use SoapUi if needed for the same.
Few this that we need to upderstand when making query using REST call we need to follow fews rules
1- Our request should always follow this patter
http://myserver:portnumber/index/type
Additional Index must be in lower case, otherwise it throws an Exception.
In terms of RDBMS:-
Index= Database
type=Table
document= one single row in that table
field = table column
We also need to know few of the basic ElasticSearch Commands
HTTP Request Type Usage
GET To get/select/read data from ElasticSearch engine
POST To create/update data to ElasticSearch engine
PUT To create/update data to ElasticSearch engine
DELETE To delete existing data from ElasticSearch engine
'- Create operation :-
'- Read operation:-
To read data we should use “_search” at the end of the read API URL.
'- Update Operation
Verifying the data is updated
'- Delete Operation
Refer below URL:-
https://www.elastic.co/webinars/getting-started-elasticsearch?baymax=optimize&elektra=product-elasticsearch&storm=hero&rogue=watch-video
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html